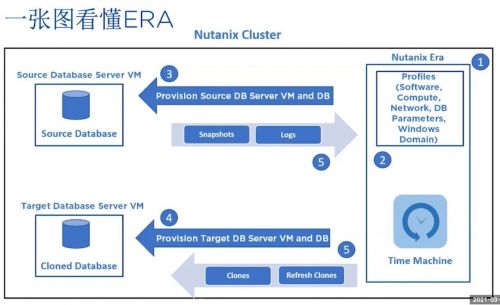
分布式应用中的缓存方案(二) 数据库缓存的实践与演进
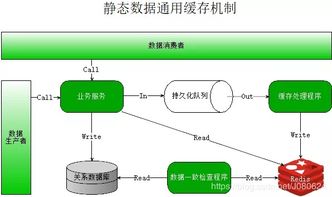
在分布式系统中,数据库缓存作为提升性能、降低延迟的关键技术,其重要性不言而喻。本文将继续探讨数据库缓存的常见方案、适用场景及演进方向。
一、数据库缓存的核心价值
数据库缓存的核心目标在于减少对底层数据库的直接访问,通过将热点数据存储在内存中,大幅提升数据读取速度。在高并发场景下,缓存能够有效减轻数据库压力,避免因频繁I/O操作导致的性能瓶颈。
二、常见的数据库缓存方案
- 查询缓存(Query Cache)
- 适用于重复查询频繁的场景,如MySQL的查询缓存机制(注:MySQL 8.0已移除)。
- 优点:自动缓存SQL结果,无需额外编码。
- 缺点:表数据变更时缓存易失效,且在高并发写入场景下可能带来性能开销。
- 应用层缓存(如Redis、Memcached)
- 将缓存置于应用层,通过键值对存储热点数据。
- 优点:灵活性高,支持丰富数据结构,可跨服务共享缓存。
- 缺点:需要显式管理缓存一致性,增加系统复杂度。
- 数据库内置缓存(如Oracle Buffer Cache、InnoDB Buffer Pool)
- 数据库自身管理的内存缓存,用于缓存数据页和索引。
- 优点:对应用透明,自动优化数据访问。
- 缺点:受限于单机内存,扩展性较弱。
三、缓存一致性的挑战与策略
缓存与数据库的数据一致性是分布式系统的经典难题。常用策略包括:
- 缓存穿透:查询不存在的数据时,可能导致请求直达数据库。可通过布隆过滤器或缓存空值缓解。
- 缓存雪崩:大量缓存同时失效引发数据库压力激增。可设置随机过期时间或采用熔断机制。
- 缓存更新策略:如Cache-Aside(先更新数据库再删除缓存)、Write-Through(同步更新缓存与数据库)等,需根据业务权衡选择。
四、演进方向:智能化与多级缓存
- 智能缓存预热:基于机器学习预测热点数据,提前加载至缓存。
- 多级缓存架构:结合本地缓存(如Caffeine)与分布式缓存(如Redis),形成多层次缓存体系,兼顾速度与扩展性。
- 数据库与缓存融合:如TiDB、AWS Aurora等新型数据库,将缓存机制深度集成,简化开发负担。
五、实践建议
- 监控先行:通过指标(命中率、延迟)持续评估缓存效果。
- 渐进式优化:从核心业务开始引入缓存,避免过度设计。
- 容灾设计:缓存故障时需有降级策略(如直接读库),保障系统可用性。
数据库缓存并非银弹,需结合业务特点灵活选型。在“进无止境”的技术道路上,持续平衡性能、一致性与复杂度,方能构建稳健的分布式系统。
---
本文灵感来源于小小默在CSDN博客的技术分享,结合分布式应用场景进行了拓展与。
如若转载,请注明出处:http://www.chnopener.com/product/18.html
更新时间:2026-06-19 22:15:23