高容量大并发数据库服务 分布式架构设计的技术内核与演进之路
在当今数据驱动的时代,业务系统对数据库服务的需求已从简单的数据存储,演变为对海量数据处理能力、超高并发访问支持以及近乎不间断可用性的严苛要求。高容量、大并发的数据库服务已成为支撑互联网、金融科技、物联网等核心业务的基石。实现这一目标的关键,在于其背后的分布式架构设计。本文将深入解读这一领域的核心思想与技术实践。
一、核心挑战:为何需要分布式架构?
传统单机或主从架构数据库在面对以下挑战时往往力不从心:
- 容量瓶颈:单台服务器的存储(磁盘)、计算(CPU)、内存资源存在物理上限,无法承载TB乃至PB级的数据增长。
- 性能瓶颈:单一节点的处理能力有限,当每秒查询率(QPS)达到十万、百万甚至更高量级时,响应时间急剧增加,系统濒临崩溃。
- 可用性风险:单点故障将导致整个服务不可用,无法满足现代业务对99.99%乃至更高可用性的要求。
- 扩展不灵活:垂直扩展(升级硬件)成本高昂且存在天花板,无法实现快速、平滑的弹性伸缩。
分布式架构正是为系统性解决这些问题而生,其核心思想是将数据分散、将计算并行、将风险隔离。
二、分布式架构设计的核心维度
一个成熟的高容量大并发数据库服务,其分布式设计通常围绕以下几个维度展开:
1. 数据分片(Sharding)
这是解决容量与写入并发瓶颈的基础。
- 原理:将逻辑上的完整数据集,按特定规则(如范围、哈希值、业务主键)水平切分,分散到多个物理数据库节点(分片)上。
- 关键考量:
- 分片键选择:需具备业务普适性,能保证数据均匀分布,避免“热点”分片。常用策略包括用户ID哈希、时间范围等。
- 路由机制:应用或中间件如何准确、高效地将查询路由到正确的分片。透明化路由(对应用层屏蔽分片细节)是重要目标。
- 再平衡:当集群扩容或缩容时,数据如何自动、平滑地在节点间迁移,并最小化对服务的影响。
2. 多副本与高可用(Replication & HA)
这是保障服务可靠性与读并发的关键。
- 原理:每个数据分片在多个物理节点上保存副本(通常一主多从)。
- 读写分离:主副本通常负责写入,从副本同步数据并承担读请求,极大提升读吞吐量。
- 故障转移:当主节点故障时,通过共识算法(如Raft、Paxos)快速、自动地从从副本中选举出新的主节点,实现服务不中断。
- 一致性权衡:在跨地域多副本场景下,需要在强一致性、弱一致性和最终一致性之间做出权衡,以满足不同业务场景的需求。
3. 分布式事务与一致性
这是分布式数据库领域最复杂的挑战之一。
- 挑战:一个事务可能涉及多个分片上的数据更新,需要保证所有节点要么全部成功,要么全部失败(ACID中的原子性)。
- 主流方案:
- 两阶段提交(2PC):经典的强一致性方案,但存在协调者单点风险和阻塞问题。
- TCC(Try-Confirm-Cancel):适用于业务逻辑可清晰拆分的场景,通过应用层补偿实现最终一致性。
- 基于全局时钟(如Spanner的TrueTime):提供跨分片的强一致性和外部一致性,但依赖精密时钟同步。
- 最终一致性:通过消息队列、异步复制等方式,在业务可接受的延迟内达成数据一致,是许多互联网场景的选择。
4. 弹性伸缩与资源调度
云原生时代,数据库服务需具备“弹性”这一核心属性。
- 在线扩缩容:支持在不中断服务的情况下,动态增加或减少计算/存储节点。这要求数据分片和负载均衡策略能动态调整。
- 存储与计算分离:将数据持久化存储在共享、可无限扩展的对象存储或分布式文件系统中,而计算节点(负责SQL解析、执行引擎)无状态化,可以独立、快速地弹性伸缩。这是现代云数据库(如Snowflake, Aurora)的典型架构。
- 智能化调度:基于工作负载预测和实时监控,自动调度资源,实现成本与性能的最优平衡。
三、典型架构模式演进
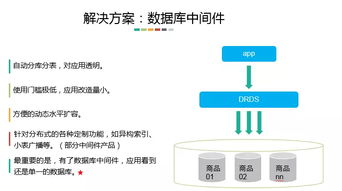
- 分库分表中间件模式:早期经典方案,如ShardingSphere、MyCAT。在应用层或代理层进行分片逻辑处理,底层仍是多个独立的MySQL/PostgreSQL实例。开发运维复杂度较高。
- 原生分布式数据库:如Google Spanner、TiDB、OceanBase、CockroachDB。将分布式能力内置于数据库内核,对外提供单一逻辑数据库视图,极大简化了应用开发。它们在全局一致性、弹性伸缩上做了深度融合。
- 云托管分布式服务:如Amazon Aurora、Azure Cosmos DB、阿里云PolarDB。将分布式复杂性全部交由云平台管理,提供完全托管、一键伸缩、按量付费的服务,代表了未来的主流方向。
四、技术选型与未来展望
选择高容量大并发数据库服务时,需综合评估:
- 业务场景:是强事务的OLTP,还是复杂分析的OLAP,或是混合负载(HTAP)?
- 一致性要求:是否需要跨区域的强一致?
- 扩展模式:预期是线性平滑扩展,还是阶段性扩容?
- 生态与迁移成本:与现有技术栈(如SQL方言、驱动、运维工具)的兼容性。
分布式数据库架构将继续向更透明、更智能、更融合的方向演进:
- 全托管与Serverless:开发者完全无需关心基础设施,数据库根据负载自动伸缩至零,实现极致成本效益。
- AI驱动的自治运维:利用机器学习进行故障预测、性能调优、索引推荐和安全管理。
- 多模与一体化:在同一数据平台上,同时高效支持事务、分析、图计算、流处理等多种负载,打破数据孤岛。
###
高容量大并发数据库服务的分布式架构设计,是一场在数据一致性、系统可用性、处理性能与扩展弹性之间寻求精妙平衡的艺术与工程实践。它不仅是技术的堆砌,更是对业务深刻理解的体现。随着云计算的普及和硬件技术的发展,分布式数据库正变得越来越“无形”,但其核心的设计思想——通过分散与协同来驾驭数据洪流——将始终是支撑数字世界稳健运行的基石。
如若转载,请注明出处:http://www.chnopener.com/product/6.html
更新时间:2026-06-19 08:20:56